


The Artificial Investor - Issue 39: The next big thing is…small

My name is Aris Xenofontos and I am an investor at Seaya Ventures. This is the weekly blog of the Artificial Investor that analyses one of the main top AI developments of the last seven days.
This Week’s Story: Microsoft and Amazon launch small language models that beat much-larger competitors
Most headlines last week were caught by the launch of Google’s new large language model (LLM), Gemini 2.0, which generates images and audio, is faster and cheaper to run than Google’s previous flagship model and is meant to make AI agents possible. Nevertheless, in the same week, two other hyperscalers have also launched new models: Microsoft launched Phi-4 and Amazon launched the Nova model family, including Nova Micro. While this certainly speaks to the commoditisation of AI models that we have discussed in the past, there is another piece of news that is very interesting and capable of transforming entire industries. Today’s small models that can run on a personal computer are as good as the LLMs that wowed the world about two years ago.
How fast are small language models (SLMs) catching up with LLMs? What is the technical secret sauce that is driving this trend? What are the implications for the AI ecosystem? What does this mean for future investment opportunities?
If you prefer to listen to this issue, click here for the audio version.
Powered by ElevenLabs

💭 First things first: what is an SLM? SLMs are similar to LLMs, in the sense that they are also generative pre-trained language models based on the transformer architecture. However, they are smaller. How much smaller? While the lower bound is easy, in the hundreds of millions of parameters, the upper bound is not officially defined. We will set the definition based on a reference point that anyone can relate to: the size of model one can comfortably run on a personal computer.
Many language model developers have launched smaller versions of their models, such as the Flash version of Google’s Gemini version 1.5 (32 billion parameters) or Mistral AI's Mixtral 8x22B (39 billion active parameters). Typically a model of 30 billions of parameters requires a GPU with double the size in memory, i.e. 60GB. The best consumer GPU chips have a memory of 24GB (e.g. NVIDIA GeForce RTX 4090 or AMD Radeon RX 7900 XTX), which comfortably runs language models of about 14 billion parameters. However, a 30B model, for instance, cannot run on a personal computer without any manipulation that affects its accuracy (e.g. quantization). Therefore, using the PC threshold, we exclude the subset of language models at around 20-40 billions of parameters, but we include the smaller versions of models from many leading language model developers: Microsoft’s Phi-4 14B, OpenAI’s GPT-4o mini 9B, Google’s Gemini 1.5 Flash 8B, Meta’s Llama 3.1 8B, Anthropic’s Claude 3.5 Haiku 8B and Alibaba’s Qwen 2.5 8B.

We must acknowledge here that as consumer-grade GPUs get stronger, this threshold will move higher and incorporate more models. Also, another SLM category exists, which is the one of models that can comfortably run on a smartphone (currently at 2 billions of parameters). But, we shall leave that for another edition.
📉 Recent developments
Language models that can run on a PC have been out for a while, so what makes ‘now’ so special? The answer is: performance.
The development of language models has seen significant advancements in the last few years, and particularly since November 2022 and when GPT-3.5 was introduced to the public as a consumer application (ChatGPT). GPT-3.5 was perhaps the first model that was good enough to bring significant productivity gains to non-technical knowledge workers and made every AI enthusiast visualise what a future with super intelligence would look like. GPT-3.5 scored 70 out of 100 at the MMLU benchmark in a 5-shot setting (this means having five interactions to help the model answer language-understanding tasks. Note: we have talked in the past about the various weaknesses and limitations of such benchmarks, but we need something to go by in our analysis). This score was later on beaten by other private LLMs, such as Google’s Gemini Pro models and eventually beaten by models freely-available to everyone, such as Meta’s Llama series. The leading position is currently held by OpenAI again, with its latest state-of-the-art LLM, GPT-4.
While it has taken billions of dollars to train these large models, another wave of innovation has taken place in the SLM front. It took about 2 years for a paid closed-source SLM (Microsoft Phi-3 Mini) and about 2.5 years for a free open-source (Meta LLama 3.1 8B) to beat the performance of GPT-3.5, the LLM that wowed the world in November 2022. This trend seems to continue, as it also took about 2 years for a paid closed-source SLM (the recently-released Microsoft Phi-4) to reach the performance of GPT-4, the leading LLM back in May 2024. We expect this trend to accelerate as LLM performance sees diminishing returns with higher scale (as we wrote in issue 37). This is mindblowing.

🍲 What is the secret technical sauce?
Our initial hypothesis was that all this has become possible due to model reduction techniques, such as quantization (making models lighter by limiting them in working with numbers with less decimals), sparse attention (selecting a smaller set of more relevant words used to predict the next word in a response), etc (see issue 37 for more detailed explanations of these techniques). While these techniques are indeed used by many AI model developers, the secret sauce doesn’t seem to lie there.
Although it is hard to know what’s happening behind the scenes, based on the release announcements of the various SLM developers, it looks like there are two factors that are driving the SLM catch-up effect: i) distillation and ii) data quality.
Distillation (as laid out in 2015 by the recently-awarded Nobel-prize winner and godfather of AI, Geoffrey Hinton) involves using a pre-trained LLM (teacher) to train a smaller model (student) to emulate it. By transferring knowledge from the larger model, the smaller model can achieve higher performance than if it were trained directly on the dataset. This also makes us feel good about spending billions of dollars to pre-train LLMs.
Many lines have been written about the debate of data quantity vs. data quality in model training, as well as the fact that we may be running out of text training data soon. Microsoft researchers emphasized the importance of curated, high-quality datasets in training Phi-3 Mini efficiently. This approach allowed the small model to achieve performance levels comparable to larger models trained on vast amounts of more diverse data. In their latest model release (Phi-4), the Microsoft team also highlighted the importance of synthetic data. Phi-4 was trained using over 50 synthetic datasets containing approximately 400 billion tokens. Microsoft used AI to rewrite web content into test questions and generate corresponding answers, and carefully curated the training data by incorporating content from acquired academic books and Q&A datasets.
⚙️ Implications for the Infrastructure Layer
The implications of the SLM trend for the AI Infrastructure Layer are profound and centered around the model development segment.
Smaller model size has led to lower computational resource requirements in training. Although there is not much official data out there, we did our digging and got somewhere. Microsoft had stated that training Phi-2, a 2.7 billion-parameter model released in December 2023, took 14 days on 96 pieces of A100 Nvidia GPU chips. Assuming a renting cost of 2 dollars per hour (it currently costs less than half that, but we are being conservative due to the difference of a year in the data), the total training cost would be 50,000 dollars. Even if an 8-billion-parameter model took four times the computational resources, this would take it to 200,000 dollars. On the other hand, Sam Altman stated that GPT-4's training expenses were more than 100 million dollars. The significant reduction in training small models that perform at very high standard (albeit two years later than their comparable LLMs), means that more developers are able to train their own models. The SLM trend is democratising access to the AI infrastructure market.
💻 Implications for the Application Layer
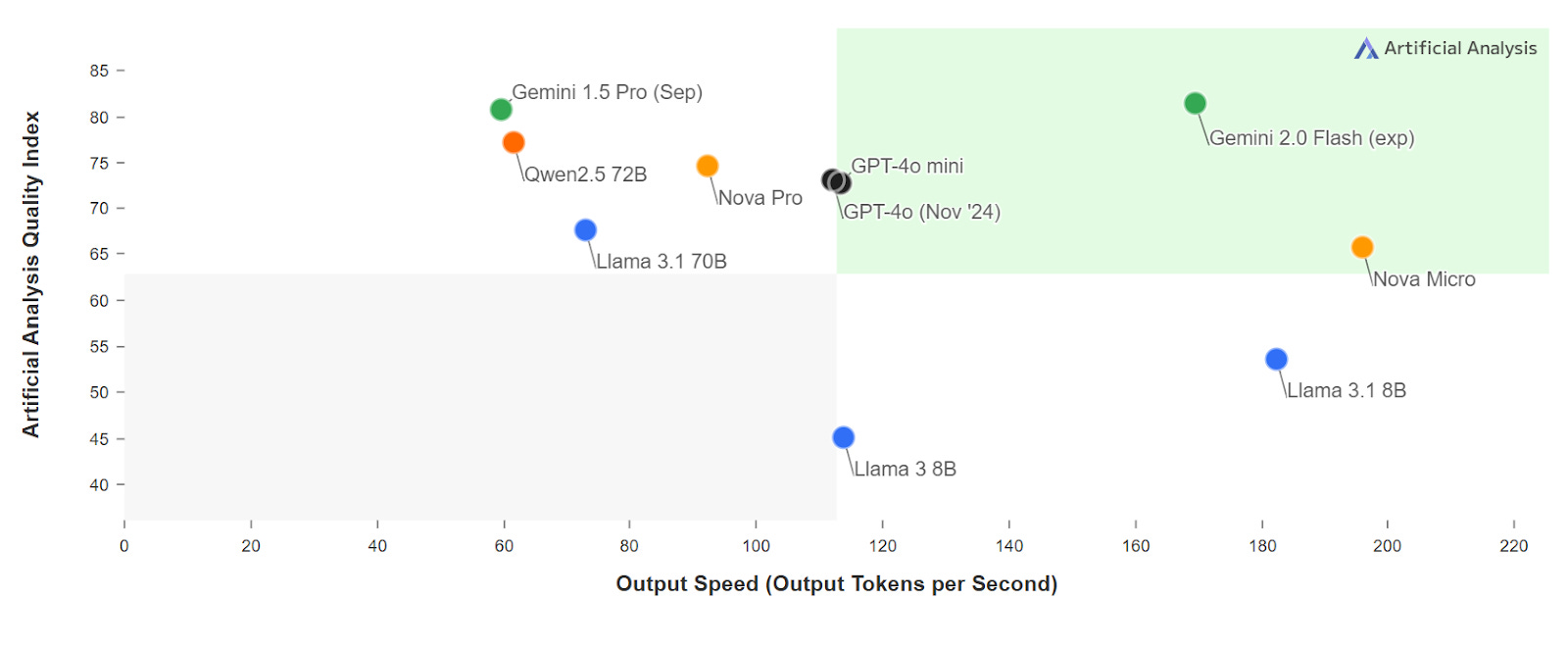
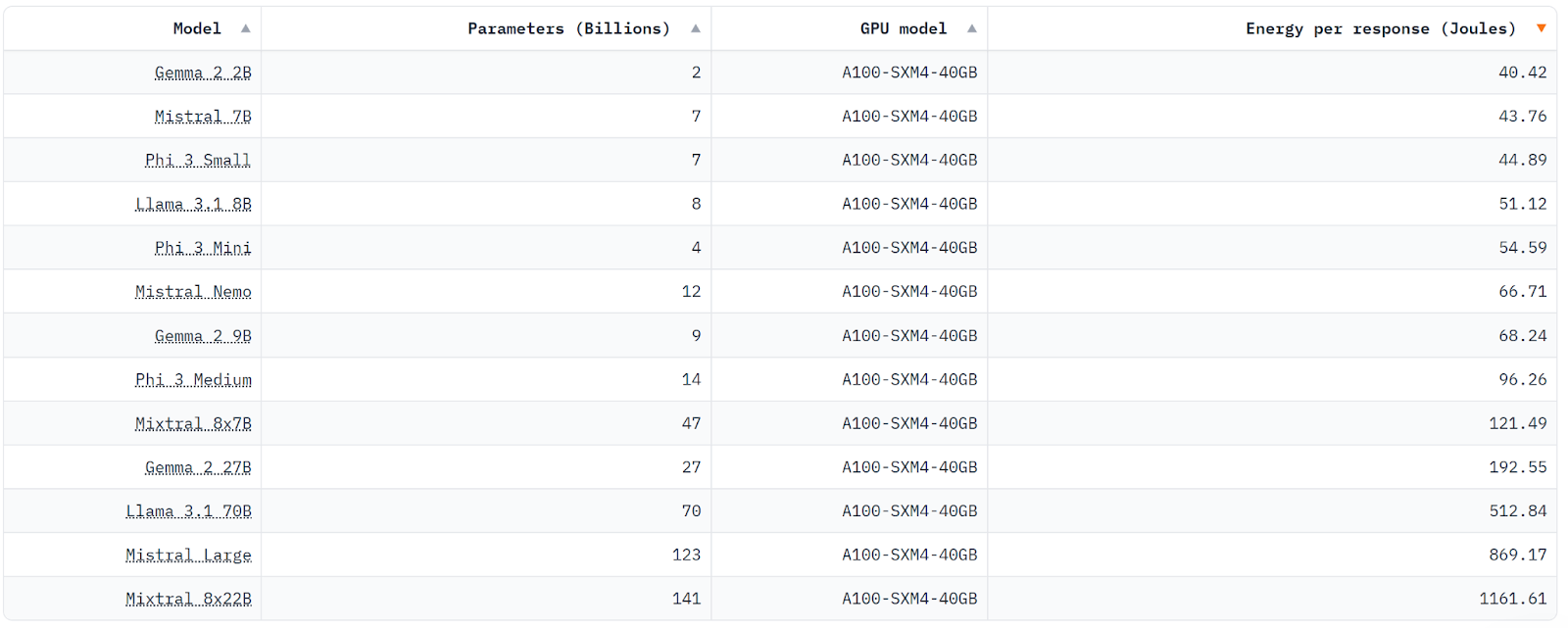
Smaller model size has led to lower computational resource requirements during usage (aka inference), which in turn has resulted in faster response speeds measured in output tokens per second (2x-3x faster for comparable models) and huge energy efficiencies (up to 10x lower energy consumption for comparable models).
Model quality index (aggregate benchmark scores) vs. output speed
Energy consumption per model response (Joules) when running on an Nvidia A100 GPU chip
As a result, small models can be used in a range of cases where LLMs would struggle, such as:
Devices with limited hardware capabilities
Devices that run 24/7 and have limited battery storage or cooling capabilities due to size or operating in special conditions
Use cases where latency and speed of response are key, e.g. real-time machine-to-machine communication
Use cases where data privacy is critical, as small models are deployed on device and don’t require data to travel through the Cloud
Use cases of deploying AI at massive scale, where hardware and running costs can ramp up fast to significant figures
🔮 Looking ahead
In a world where AI funding is dominated by the Infrastructure Layer, we already see a trend with more funding going into AI efficiency and scalability. Also, as venture capital money slowly shifts from the Infrastructure to the Application Layer, we expect small language models to get more attention and power a great part of the AI applications of the future.
Smaller models allow startups to enter markets previously dominated by Tech giants with more resources. In addition, smaller models help avoid AI compliance costs, at least in Europe, where regulation is linked to the size of the model and SLMs remain far below regulatory thresholds. Finally, we expect small model innovation to expand to multimodal applications, covering audio, image and, eventually, video.
Some of the sectors that we are tracking closely and expect to benefit from these tailwinds are:
IndustryTech, in particular predictive maintenance use cases, where SLMs can analyze and interpret maintenance logs and sensor data to predict when machines are likely to fail or need servicing.
Supply Chain and Logistics, where SLMs can automate communication tasks, such as generating and interpreting emails or messages regarding inventory levels, shipment statuses or delivery schedules.
Manufacturing Operations, where SLMs can help interpret complex manufacturing instructions with high precision, ensuring they are correctly followed by providing clarifications in natural language.
Energy Management, where SLMs can analyse energy usage data and operational schedules, and suggest optimisations that reduce energy consumption without impacting productivity.
🧑🎄 Switching gears, while we are approaching the holiday season, we are preparing a critical review of our 2024 AI predictions and putting together our new predictions for the year to come. Stay tuned.